코딩 테스트를 위한 자료 구조와 알고리즘 with C++
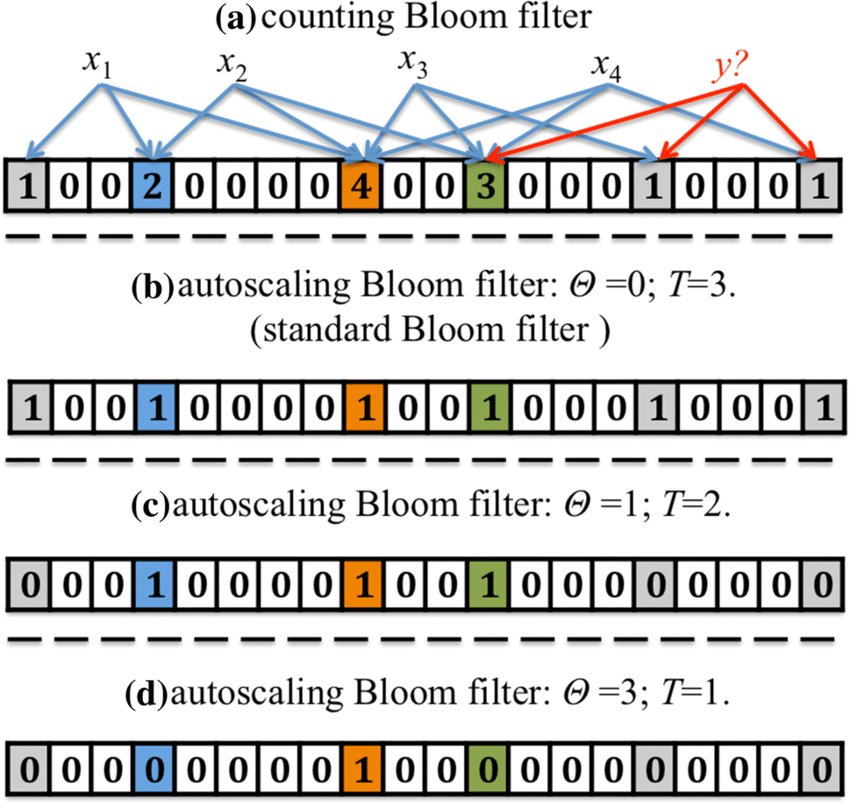
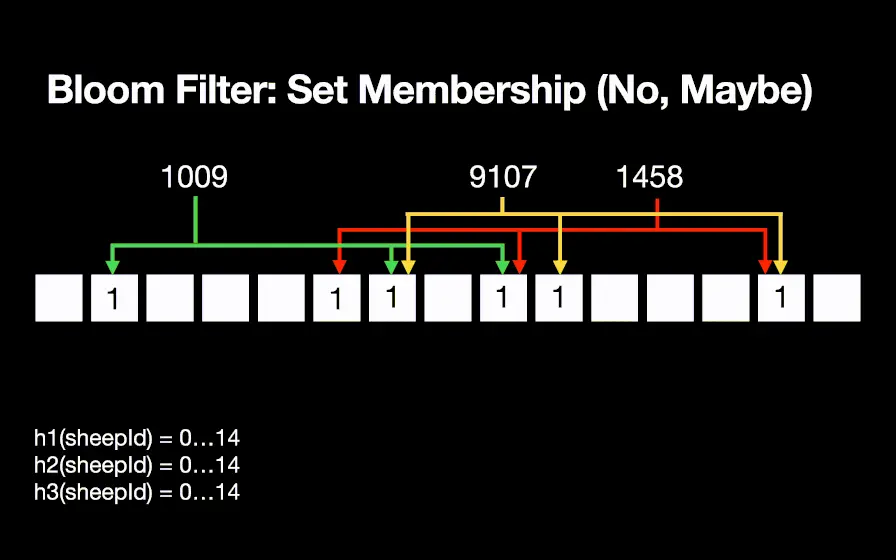
블룸 필터
- 뻐꾸기 해싱과 마찬가지로 여러 개의 해시 함수를 사용한다.
- 실제 값을 저장하지 않으며 키가 있는지 없는지 여부만 알 수 있다.
- 삽입 시 모든 해시 함수의 값에 해당하는 비트를 1로 설정한다.
확인한 모든 비트의 값이 1이면 키가 존재한다는 뜻이고, 모두 0이면 존재하지 않는다는 뜻이다. - 해시 테이블에 비해 공간 효율이 매우 높지만 결정적(Deterministic) 결과 대신 부정확한 결과를 얻을 수 있다.
거짓-부정(False negative)이 없는 것은 보장하지만 거짓-긍정(False Positive)은 나올 수 있다.
※ 거짓-부정: 있는데 없다고 하는 경우
※ 거짓-긍정: 없는데 있다고 하는 경우
블룸 필터를 사용하는 경우
- 데이터 양이 너무 많아 해시 테이블조차 버거운 경우
- 값이 아닌 키의 존재만 확인하면 되는 경우
- 거짓-긍정이 있어도 괜찮은 경우
블룸 필터의 실제 사용 예
- 대규모 이메일 시스템의 아이디 중복 검사
- 새로운 광고 선택 알고리즘
사용자가 이미 본 모든 광고의 ID를 블룸 필터에 저장하고, 블룸 필터에서 존재하지 않는다고 판정한 광고를 새로 보여준다.
#include <iostream>
#include <vector>
using namespace std;
class bloom_filter
{
vector<bool> data;
int nBits;
public:
bloom_filter(int n) : nBits(n), data(vector<bool>(n, false)) { }
void lookup(int key)
{
int hs1 = hash(0, key);
int hs2 = hash(1, key);
int hs3 = hash(2, key);
if (data[hs1] & data[hs2] & data[hs3])
cout << key << ": 있을 수 있음" << endl;
else
cout << key << ": 절대 없음" << endl;
}
void insert(int key)
{
int hs1 = hash(0, key);
int hs2 = hash(1, key);
int hs3 = hash(2, key);
data[hs1] = data[hs2] = data[hs3] = true;
cout << key << "을(를) 삽입: ";
print();
}
void print()
{
for (bool b : data)
cout << b << " ";
cout << endl;
}
private:
int hash(int num, int key)
{
switch (num)
{
case 0 : return key % nBits;
case 1 : return (key / 7) % nBits;
case 2 : return (key / 11) % nBits;
}
}
};
void main()
{
bloom_filter bf(7);
bf.insert(100);
bf.insert(54);
bf.insert(82);
bf.lookup(5);
bf.lookup(50);
bf.lookup(20);
bf.lookup(54);
}
출력
100을(를) 삽입: 1 0 1 0 0 0 0
54을(를) 삽입: 1 0 1 0 1 1 0
82을(를) 삽입: 1 0 1 0 1 1 0
5: 있을 수 있음
50: 절대 없음
20: 절대 없음
54: 있을 수 있음'자료구조 & 알고리즘 > 코딩 테스트를 위한 자료 구조와 알고리즘 with C++' 카테고리의 다른 글
| 분할 정복(Divide and Conquer) (0) | 2023.02.15 |
|---|---|
| 알고리즘(Algorithm) (0) | 2023.02.14 |
| 뻐꾸기 해싱(Cuckoo hashing) (0) | 2023.02.11 |
| 해시 테이블의 충돌: 열린 주소 지정 - 이차함수 탐색 (0) | 2023.02.10 |
| 해시 테이블의 충돌: 열린 주소 지정 - 선형 탐색 (0) | 2023.02.09 |
